
Our information ecosystem is in trouble. Here’s how we can fix it. Part II
By Tessa Sproule
FROM THE MID-90s until September 2001, the web was largely a ‘nice to have’ for most legacy media organizations. When it came to infrastructure spending, faced with a decision to invest in a new suite of cameras for the field or a robust server farm, investing in the tools of creation would win every time.
I had been working within the CBC’s first web efforts since 1996. At CBC.ca, we had managed traffic in the thousands, occasionally hundreds of thousands. In the days after September 11th, millions were trying to squeeze through a pipe that simply wasn’t equipped to handle it. (The nostalgic in me imagines some of that traffic getting stuck in the original server built by a CBC Radio technician in a closet in the early 90’s — the original host of CBC.ca.)
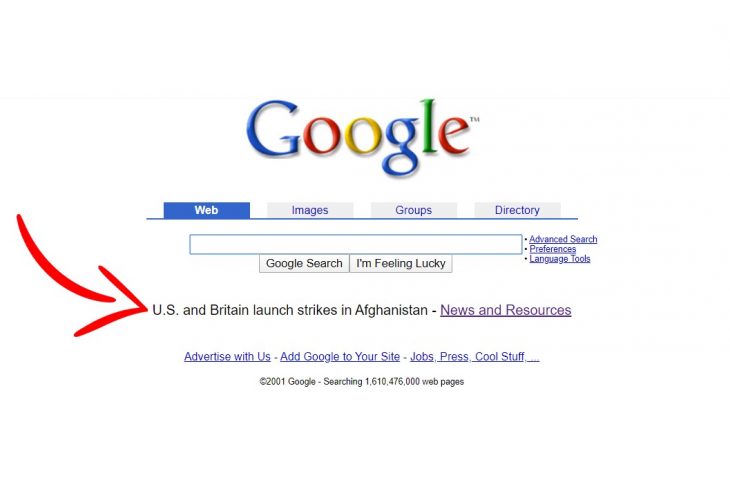
(The screen grab above is from Google.com (October 9, 2001, Wayback Machine). While Google did not agree to post links directly on its (very tidy!) homepage, the company did create a “News and Resources” section on the site to point to news providers and list direct links to articles suggested by media companies such as CBC.)
The CBC’s patchwork, online server infrastructure was no match for the the traffic from the events of September 11, so we called Google.
CBC News joined other media organizations — Canadian, American and international — with a simple ask: if we send Google direct links to the most important articles on our websites, could Google list direct links on its homepage? (It’s a process I’d initiated with Yahoo! a few years earlier when I ran CBC’s first online arts and entertainment news “portal”, Infoculture.)
“Human-in-the-loop” intervention by journalists was something the tech platforms needed and wanted. BigTech needed help putting context around the relentless barrage of news; they needed us to tell them what our stories were about, feeding data signals into their systems.
Our servers were melting. Google had the server heft, and 9/11 search queries dominated their interactions — everyone would win if we could just work together.
And there you have it — the origins of Google News.
It was an invention of the best kind — made out of necessity. At CBC, we had digital “line-up” producers emailing contacts at Google with suggestions for news articles they should link to (my now Co-CEO/Co-Founder at Vubble called home to tell her parents when her biography of Osama bin Laden was linked from Google). The headlines and links went up, and Google came back for more.

Algorithms, machine learning, the functioning processes of AI — they can only work with the signals we provide them.
For a while, it worked like that — we’d send links and mostly Google would list them. Then, as the news cycle pushed on, we went back to what we do, as journalists: getting the information,putting it together, getting it out there.
The trouble is, legacy broadcast networks like CBC were so invested in old infrastructure (and for some, bountiful advertising revenue), we let go of the ‘getting it out there’ piece. This lack of innovation and imagination for how audience behaviour was changing was exploited with tremendous effect by the social media platforms that emerged in the years that followed with the rise of “Web 2.0”. And it was exploited again by dark players who would later weaponize the frailties of those same platforms to wreak havoc on elections, human rights and ultimately our understanding of ourselves.
Getting trustworthy, quality news content in front of citizens who need to see and understand it is not a new thing. It is a core mission of journalists and the information media ecosystems of every democracy on Earth. We should have done better back on 9/11, and we must carefully consider our approaches to digital distribution now as artificial intelligence automates editorial functions in the newsroom today and tomorrow.
How BigTech won the first round
In the fall of 2002, Google officially launched Google News — a technological solution to the problem of ‘how can we help people find meaningful, relevant information on the web?’ It was a problem legacy media had failed to address, handing it to BigTech to manage. And they did.
An interesting side-note: Google News was followed by Gmail (2004), Google Maps (2005) and YouTube (2005). Google News was a precursor to all of it. Tech companies like Google could see where conventional media was failing the emerging digital audience, and they filled that void.
To their credit, they made it better — and for a time, the tools Google (later joined by Facebook, Twitter and the whole dang FAANG squad) came up with were irresistible to legacy media as we tried to sort out this “internet thing”.
Then, Google did what all tech platforms do — they began automating their systems; at CBC, we had fewer and fewer opportunities to connect with the Google people to pitch for our articles to show up — and eventually they just stopped answering the phone and responding to our emails.
Google News was digital publishing on steroids — it was super efficient. If you could get your article listed (it was pretty much only text back then), you got audience to it. Exponentially bigger audience numbers were coming directly from the BigTech platform referrals, eclipsing the traffic a media company could achieve alone.
Then, Google did what all tech platforms do — they began automating their systems; at CBC, we had fewer and fewer opportunities to connect with the Google people to pitch for our articles to show up — and eventually they just stopped answering the phone and responding to our emails. Eventually those friendly Google people we’d dealt with in the early days after September 11 were replaced by algorithms to read, prioritize and distribute our articles — serving millions of people at click of a mouse, something we simply couldn’t do with our “legacy” systems.
Content creators, publishers and distributors must win the next round
Algorithms, machine learning, the functioning processes of AI — they can only work with the signals we provide them. We give a few instructions, and based on those signals, the machines make predictions — and ultimately they will make decisions (if we let them — we really should be more careful about when that should happen).
The earliest versions of Google’s own search system relied on “regular people” like you or me, helping to identify the content of a web page and the topics it covered. For example, DMOZ, a collaborative editorial project, played a significant role in helping Google understand what websites of the day were really about, by enlisting an army of human volunteers to annotate and validate the context of what a web page might be about. Because computers can’t really think.
Today, the world’s biggest technology companies are using thousands of human workers around the world to tell computers what to “think”. It is not exactly futuristic work. It is mundane but necessary data grunt-work; the manual annotation of content, data-tagging has exploded as an industry. Most tech executives don’t discuss the labor-intensive process that goes into its creation. But I will — and I will tell you that AI is learning from humans. Lots and lots of humans.

Data tagging accounts for 80 percent of the time spent building AI technology. At Vubble, we insist on a “journalist-in-the-loop” approach to this work when dealing with news/information content.
Before an AI system like my company’s can learn, people have to label the data it learns from. This work is vital to the creation of artificial intelligence used in systems for self-driving cars, surveillance and automated health care.
The market for data labeling passed $500 million in 2018 and it will reach $1.2 billion by 2023, according to the research firm Cognilytica. Data tagging accounts for 80 percent of the time spent building AI technology.
BigTech keeps quiet about this work; they face growing concerns about privacy and the mental health of “taggers” (cousins of the “content moderators”). At Vubble, we insist on using local journalists to data tag the long-tail information video for some of the world’s leading news organizations. That’s because, as journalists, we know that context is everything, and humans still beat today’s earthworm-brain AI.
AI is great when we use it to spot a cancerous mole — it is mind-blowing and awesome that a machine can spot anomalies in thousands of images in a millisecond, something a human doctor, no matter how brilliant, could ever do. Er… hold on! Here’s an AI engineer from Google itself, telling us that the human doctors out-performed the AI in some cases too. He ends by saying AI is best in compliment to the human brain. We lift each other up.
Today, we need to work together, with machines, in ways we have never worked before. If you stop reading here, I just ask as that you keep this in mind: We all need to think carefully about how we work with AI going forward. The decisions we let it make on our behalf. The signals we give it to base those decisions on.
(This is part two of four. Next time, we’ll did into the weaknesses of AI, and how that’s opening up new opportunities for the news media industry)
Please click here for the first portion of this excellent analysis.
Tessa Sproule is the co-founder and co-CEO of Vubble, a media technology company based in Toronto and Waterloo, Canada. Vubble helps media and educational groups (like CTV News, Channel 4 News, Let’s Talk Science) by cloud-annotating news video, building tools for digital distribution and generating deeply personalized recommendations via Vubble’s machine-learning platform.

